Latest Sessions
View All Sessions
S23 | Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
Zhihan Yang (Cornell) presents RePlaid, revisiting the Plaid continuous diffusion language model to challenge the view that continuous diffusion is less scalable than discrete diffusion. RePlaid needs only 20x more compute than an autoregressive model to match its perplexity, close to MDLM at 14x and far below the 64x once attributed to the original Plaid, and it reaches a state-of-the-art perplexity of 22.1 among continuous diffusion language models on OpenWebText.
Diffusion has drawn wide attention in language modeling, yet continuous diffusion has looked less scalable than discrete approaches. This work challenges that belief. The authors revisit Plaid, a likelihood-based continuous diffusion language model, and construct RePlaid by aligning its architecture with modern discrete diffusion language models. In this unified setting they establish the first scaling law for continuous models that rivals discrete ones: RePlaid sits within a 20x compute gap of autoregressive models, outperforms Duo while using fewer parameters, and outperforms MDLM in the over-trained regime. Against recent continuous models on OpenWebText, RePlaid reaches a new state-of-the-art perplexity bound of 22.1 with better generation quality. The paper also offers theory for why likelihood-based training helps. Optimizing the noise schedule to minimize the variance of the ELBO naturally yields linear cross-entropy over time, which spreads denoising difficulty evenly without any case-specific time reparameterization. Optimizing token embeddings via likelihood creates structured geometries and drives most of the likelihood gain. Together these results suggest that continuous diffusion, when trained via likelihood, is a competitive and scalable alternative to discrete diffusion.

S22 | Nemotron-Labs-Diffusion: A Tri-Mode Language Model
Nemotron-Labs-Diffusion unifies autoregressive, diffusion, and self-speculation decoding in one architecture, trained with a joint objective so it can switch modes to keep throughput high. The two objectives prove complementary: diffusion improves lookahead planning, while autoregression supplies left-to-right linguistic priors.
Nemotron-Labs-Diffusion is a tri-mode language model that unifies three decoding strategies in a single architecture: autoregressive (AR), diffusion, and self-speculation. Autoregressive models decode one token at a time, which underuses hardware at low batch sizes, while diffusion models decode many tokens per forward pass but usually trail AR in accuracy and need far more data to catch up. This work trains a single model with a joint AR-diffusion objective so it can switch modes to sustain high throughput across deployment settings and concurrency levels. The study makes three points. First, the AR and diffusion objectives are complementary: diffusion improves lookahead planning, while AR provides the left-to-right priors of natural language. Second, in self-speculation mode the diffusion path drafts tokens while the AR path verifies them, beating multi-token prediction in both acceptance rate and real-device efficiency. Third, a speed-of-light analysis shows diffusion can produce up to 76.5% more tokens per forward pass than self-speculation under an optimal sampler. The released family spans 3B, 8B, and 14B parameters with base, instruct, and vision-language variants. Nemotron-Labs-Diffusion-8B decodes six times more tokens per forward than Qwen3-8B at comparable accuracy, which translates to four times higher throughput on SPEED-Bench with SGLang on a GB200 GPU.

S21 | Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
Samson Gourevitch (École Polytechnique), Yazid Janati (MBZUAI), and Dario Shariatian (INRIA) revisit Uniform Diffusion Models (UDMs) and show that their standard parameterization is trained by a leave-one-out posterior, which predicts each clean token without seeing its own noisy observation. Correcting for this mismatch improves UDM generation, and an absorbing-state reformulation matches masked diffusion, suggesting the gap between the two comes from parameterization and sampling rather than the choice of marginals.
Samson Gourevitch (École Polytechnique), Yazid Janati (MBZUAI), and Dario Shariatian (INRIA) present their work revisiting Uniform Diffusion Models. Discrete diffusion models are usually trained by predicting clean tokens from a noisy sequence, but that prediction can be turned into reverse dynamics in several ways. For Masked Diffusion Models (MDMs) these choices largely coincide; for Uniform Diffusion Models (UDMs) they do not. This work shows that the standard plug-in parameterization for UDMs is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This exposes a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective. The authors characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score, which lets them pair either parameterization with either objective. The same conversions improve inference at no extra training cost, through an informed predictor-corrector sampler and temperature sampling applied to the leave-one-out predictor. The authors further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking step. On language modeling, leave-one-out parameterizations consistently improve UDM generation, and the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion comes less from the choice of marginals than from parameterization and sampling design.
Featured Videos
View All Videos
How did diffusion LLMs get so fast?
Techniques for accelerating diffusion LLMs, from self-distillation and curriculum learning to KV caching and block diffusion
This video discusses techniques for making diffusion LLMs faster, including self-distillation through time, curriculum learning, confidence scores for unmasking, guided diffusion (FlashDLM), approximate KV caching (dLLM-Cache, dKV-Cache), and block diffusion.
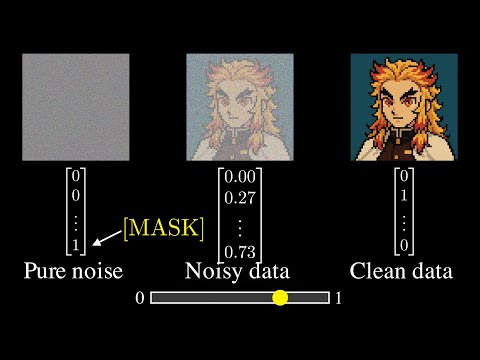
But How Do Diffusion Language Models Actually Work?
Jia-Bin Huang explores several ideas for applying diffusion models to language modeling
Most Large Language Models (LLMs) today are based on Autoregressive models (i.e., they predict texts in a left-to-right order). But diffusion models offer iterative refinement, flexible control, and faster sampling. In this video, we explore several ideas for applying diffusion models to language modeling.

Simple Diffusion Language Models
Quick introduction to Masked Diffusion Language Models (MDLM) by Alexander Rush
Quick introduction to Masked Diffusion Language Models (MDLM) by Alexander Rush
About the Reading Group
Diffusion LLMs are faster, more controllable successors to traditional LLMs and are rapidly gaining adoption. This reading group builds a community for exchanging and debating emerging ideas in this space. While our primary focus is discrete diffusion models for language, we also welcome work on other modalities and applications, such as molecular design, drug discovery, and beyond.
Meet the Organizers

Subham Sahoo
Holds a Ph.D. from Cornell Tech, where he specialized in Diffusion Language Models. He has made foundational contributions to the field, with his work deployed at scale by Google, NVIDIA, and ByteDance across language generation and drug discovery.

Justin Deschenaux
PhD student in Machine Learning at EPFL, advised by Prof. Caglar Gulcehre. Previously interned at Apple MLR. His research interests include diffusion language models, fast generative models, and generalization.
